![]()
Professional-Machine-Learning-Engineer Dumps with Free 365 Days Update Fast Exam Updates
Verified Professional-Machine-Learning-Engineer dumps Q&As - 2022 Latest Professional-Machine-Learning-Engineer Download
NEW QUESTION 13
A financial services company is building a robust serverless data lake on Amazon S3. The data lake should be flexible and meet the following requirements:
* Support querying old and new data on Amazon S3 through Amazon Athena and Amazon Redshift Spectrum.
* Support event-driven ETL pipelines
* Provide a quick and easy way to understand metadata
Which approach meets these requirements?
- A. Use an AWS Glue crawler to crawl S3 data, an Amazon CloudWatch alarm to trigger an AWS Batch job, and an AWS Glue Data Catalog to search and discover metadata.
- B. Use an AWS Glue crawler to crawl S3 data, an AWS Lambda function to trigger an AWS Batch job, and an external Apache Hive metastore to search and discover metadata.
- C. Use an AWS Glue crawler to crawl S3 data, an AWS Lambda function to trigger an AWS Glue ETL job, and an AWS Glue Data catalog to search and discover metadata.
- D. Use an AWS Glue crawler to crawl S3 data, an Amazon CloudWatch alarm to trigger an AWS Glue ETL job, and an external Apache Hive metastore to search and discover metadata.
Answer: B
NEW QUESTION 14
You are developing an ML model intended to classify whether X-Ray images indicate bone fracture risk. You have trained on Api Resnet architecture on Vertex AI using a TPU as an accelerator, however you are unsatisfied with the trainning time and use memory usage. You want to quickly iterate your training code but make minimal changes to the code. You also want to minimize impact on the models accuracy. What should you do?
- A. Reduce the number of layers in the model architecture
- B. Reduce the global batch size from 1024 to 256
- C. Reduce the dimensions of the images used un the model
- D. Configure your model to use bfloat16 instead float32
Answer: B
NEW QUESTION 15
You are building a model to predict daily temperatures. You split the data randomly and then transformed the training and test datasets. Temperature data for model training is uploaded hourly. During testing, your model performed with 97% accuracy; however, after deploying to production, the model's accuracy dropped to 66%. How can you make your production model more accurate?
- A. Split the training and test data based on time rather than a random split to avoid leakage
- B. Apply data transformations before splitting, and cross-validate to make sure that the transformations are applied to both the training and test sets.
- C. Add more data to your test set to ensure that you have a fair distribution and sample for testing
- D. Normalize the data for the training, and test datasets as two separate steps.
Answer: B
NEW QUESTION 16
You have trained a deep neural network model on Google Cloud. The model has low loss on the training data, but is performing worse on the validation dat a. You want the model to be resilient to overfitting. Which strategy should you use when retraining the model?
- A. Apply a dropout parameter of 0 2, and decrease the learning rate by a factor of 10
- B. Run a hyperparameter tuning job on Al Platform to optimize for the L2 regularization and dropout parameters
- C. Run a hyperparameter tuning job on Al Platform to optimize for the learning rate, and increase the number of neurons by a factor of 2.
- D. Apply a 12 regularization parameter of 0.4, and decrease the learning rate by a factor of 10.
Answer: B
Explanation:
https://machinelearningmastery.com/introduction-to-regularization-to-reduce-overfitting-and-improve-generalization-error/
NEW QUESTION 17
A gaming company has launched an online game where people can start playing for free, but they need to pay if they choose to use certain features. The company needs to build an automated system to predict whether or not a new user will become a paid user within 1 year. The company has gathered a labeled dataset from 1 million users.
The training dataset consists of 1,000 positive samples (from users who ended up paying within 1 year) and
999,000 negative samples (from users who did not use any paid features). Each data sample consists of 200 features including user age, device, location, and play patterns.
Using this dataset for training, the Data Science team trained a random forest model that converged with over
99% accuracy on the training set. However, the prediction results on a test dataset were not satisfactory Which of the following approaches should the Data Science team take to mitigate this issue? (Choose two.)
- A. Change the cost function so that false positives have a higher impact on the cost value than false negatives.
- B. Include a copy of the samples in the test dataset in the training dataset.
- C. Generate more positive samples by duplicating the positive samples and adding a small amount of noise to the duplicated data.
- D. Add more deep trees to the random forest to enable the model to learn more features.
- E. Change the cost function so that false negatives have a higher impact on the cost value than false positives.
Answer: C,E
NEW QUESTION 18
Your data science team has requested a system that supports scheduled model retraining, Docker containers, and a service that supports autoscaling and monitoring for online prediction requests. Which platform components should you choose for this system?
- A. Cloud Composer, Al Platform Training with custom containers , and App Engine
- B. Cloud Composer, BigQuery ML , and Al Platform Prediction
- C. Kubeflow Pipelines and Al Platform Prediction
- D. Kubeflow Pipelines and App Engine
Answer: C
NEW QUESTION 19
The displayed graph is from a forecasting model for testing a time series.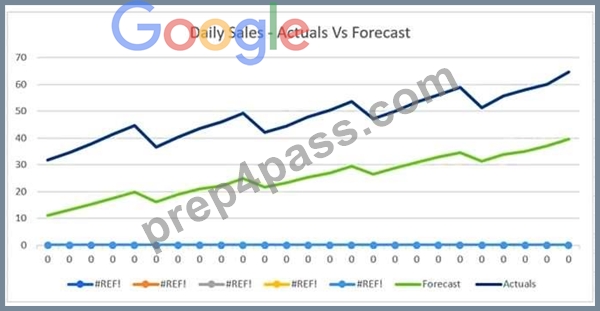
Considering the graph only, which conclusion should a Machine Learning Specialist make about the behavior of the model?
- A. The model does not predict the trend or the seasonality well.
- B. The model predicts the seasonality well, but not the trend.
- C. The model predicts both the trend and the seasonality well
- D. The model predicts the trend well, but not the seasonality.
Answer: A
NEW QUESTION 20
An interactive online dictionary wants to add a widget that displays words used in similar contexts. A Machine Learning Specialist is asked to provide word features for the downstream nearest neighbor model powering the widget.
What should the Specialist do to meet these requirements?
- A. Create one-hot word encoding vectors.
- B. Create word embedding vectors that store edit distance with every other word.
- C. Download word embeddings pre-trained on a large corpus.
- D. Produce a set of synonyms for every word using Amazon Mechanical Turk.
Answer: A
Explanation:
Explanation/Reference: https://aws.amazon.com/blogs/machine-learning/amazon-sagemaker-object2vec-adds-new- features-that-support-automatic-negative-sampling-and-speed-up-training/
NEW QUESTION 21
You work for a large technology company that wants to modernize their contact center. You have been asked to develop a solution to classify incoming calls by product so that requests can be more quickly routed to the correct support team. You have already transcribed the calls using the Speech-to-Text API. You want to minimize data preprocessing and development time. How should you build the model?
- A. Build a custom model to identify the product keywords from the transcribed calls, and then run the keywords through a classification algorithm
- B. Use the Al Platform Training built-in algorithms to create a custom model
- C. Use the Cloud Natural Language API to extract custom entities for classification
- D. Use AutoML Natural Language to extract custom entities for classification
Answer: D
NEW QUESTION 22
A Data Scientist is developing a machine learning model to predict future patient outcomes based on information collected about each patient and their treatment plans. The model should output a continuous value as its prediction. The data available includes labeled outcomes for a set of 4,000 patients. The study was conducted on a group of individuals over the age of 65 who have a particular disease that is known to worsen with age.
Initial models have performed poorly. While reviewing the underlying data, the Data Scientist notices that, out of 4,000 patient observations, there are 450 where the patient age has been input as 0. The other features for these observations appear normal compared to the rest of the sample population How should the Data Scientist correct this issue?
- A. Drop the age feature from the dataset and train the model using the rest of the features.
- B. Replace the age field value for records with a value of 0 with the mean or median value from the dataset
- C. Use k-means clustering to handle missing features
- D. Drop all records from the dataset where age has been set to 0.
Answer: D
Explanation:
Explanation
NEW QUESTION 23
Your organization's call center has asked you to develop a model that analyzes customer sentiments in each call. The call center receives over one million calls daily, and data is stored in Cloud Storage. The data collected must not leave the region in which the call originated, and no Personally Identifiable Information (Pll) can be stored or analyzed. The data science team has a third-party tool for visualization and access which requires a SQL ANSI-2011 compliant interface. You need to select components for data processing and for analytics. How should the data pipeline be designed?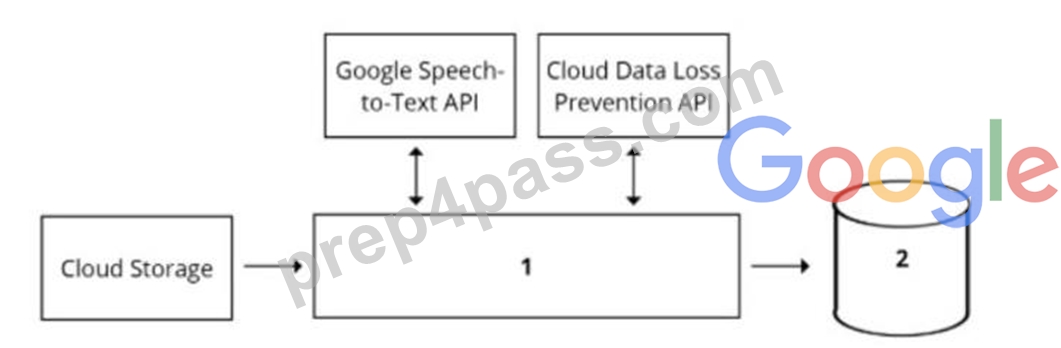
- A. 1 = Cloud Function, 2 = Cloud SQL
- B. 1 = Pub/Sub, 2 = Datastore
- C. 1 = Dataflow, 2 = BigQuery
- D. 1 = Dataflow, 2 = Cloud SQL
Answer: B
NEW QUESTION 24
A Machine Learning Specialist built an image classification deep learning model. However, the Specialist ran into an overfitting problem in which the training and testing accuracies were 99% and 75%, respectively.
How should the Specialist address this issue and what is the reason behind it?
- A. The epoch number should be increased because the optimization process was terminated before it reached the global minimum.
- B. The dimensionality of dense layer next to the flatten layer should be increased because the model is not complex enough.
- C. The learning rate should be increased because the optimization process was trapped at a local minimum.
- D. The dropout rate at the flatten layer should be increased because the model is not generalized enough.
Answer: A
Explanation:
Explanation/Reference: https://www.tensorflow.org/tutorials/keras/overfit_and_underfit
NEW QUESTION 25
A Machine Learning Specialist is designing a system for improving sales for a company. The objective is to use the large amount of information the company has on users' behavior and product preferences to predict which products users would like based on the users' similarity to other users.
What should the Specialist do to meet this objective?
- A. Build a collaborative filtering recommendation engine with Apache Spark ML on Amazon EMR.
- B. Build a combinative filtering recommendation engine with Apache Spark ML on Amazon EMR
- C. Build a content-based filtering recommendation engine with Apache Spark ML on Amazon EMR
- D. Build a model-based filtering recommendation engine with Apache Spark ML on Amazon EMR
Answer: A
Explanation:
Many developers want to implement the famous Amazon model that was used to power the "People who bought this also bought these items" feature on Amazon.com. This model is based on a method called Collaborative Filtering. It takes items such as movies, books, and products that were rated highly by a set of users and recommending them to other users who also gave them high ratings. This method works well in domains where explicit ratings or implicit user actions can be gathered and analyzed.
Reference: https://aws.amazon.com/blogs/big-data/building-a-recommendation-engine-with-spark-ml-on-amazon-emr-using-zeppelin/
NEW QUESTION 26
Your team is building an application for a global bank that will be used by millions of customers. You built a forecasting model that predicts customers1 account balances 3 days in the future. Your team will use the results in a new feature that will notify users when their account balance is likely to drop below $25. How should you serve your predictions?
- A. 1. Create a Pub/Sub topic for each user
2 Deploy a Cloud Function that sends a notification when your model predicts that a user's account balance will drop below the $25 threshold. - B. 1. Build a notification system on Firebase
2. Register each user with a user ID on the Firebase Cloud Messaging server, which sends a notification when the average of all account balance predictions drops below the $25 threshold - C. 1. Create a Pub/Sub topic for each user
2. Deploy an application on the App Engine standard environment that sends a notification when your model predicts that a user's account balance will drop below the $25 threshold - D. 1 Build a notification system on Firebase
2. Register each user with a user ID on the Firebase Cloud Messaging server, which sends a notification when your model predicts that a user's account balance will drop below the $25 threshold
Answer: A
NEW QUESTION 27
You were asked to investigate failures of a production line component based on sensor readings. After receiving the dataset, you discover that less than 1% of the readings are positive examples representing failure incidents. You have tried to train several classification models, but none of them converge. How should you resolve the class imbalance problem?
- A. Remove negative examples until the numbers of positive and negative examples are equal
- B. Use a convolutional neural network with max pooling and softmax activation
- C. Downsample the data with upweighting to create a sample with 10% positive examples
- D. Use the class distribution to generate 10% positive examples
Answer: A
NEW QUESTION 28
An online reseller has a large, multi-column dataset with one column missing 30% of its data. A Machine Learning Specialist believes that certain columns in the dataset could be used to reconstruct the missing data.
Which reconstruction approach should the Specialist use to preserve the integrity of the dataset?
- A. Listwise deletion
- B. Multiple imputation
- C. Last observation carried forward
- D. Mean substitution
Answer: B
Explanation:
Explanation/Reference: https://worldwidescience.org/topicpages/i/imputing+missing+values.html
NEW QUESTION 29
You are building a linear model with over 100 input features, all with values between -1 and 1. You suspect that many features are non-informative. You want to remove the non-informative features from your model while keeping the informative ones in their original form. Which technique should you use?
- A. After building your model, use Shapley values to determine which features are the most informative.
- B. Use L1 regularization to reduce the coefficients of uninformative features to 0.
- C. Use Principal Component Analysis to eliminate the least informative features.
- D. Use an iterative dropout technique to identify which features do not degrade the model when removed.
Answer: A
NEW QUESTION 30
Your data science team needs to rapidly experiment with various features, model architectures, and hyperparameters. They need to track the accuracy metrics for various experiments and use an API to query the metrics over time. What should they use to track and report their experiments while minimizing manual effort?
- A. Use Al Platform Training to execute the experiments Write the accuracy metrics to BigQuery, and query the results using the BigQueryAPI.
- B. Use Al Platform Training to execute the experiments Write the accuracy metrics to Cloud Monitoring, and query the results using the Monitoring API.
- C. Use Kubeflow Pipelines to execute the experiments Export the metrics file, and query the results using the Kubeflow Pipelines API.
- D. Use Al Platform Notebooks to execute the experiments. Collect the results in a shared Google Sheets file, and query the results using the Google Sheets API
Answer: C
Explanation:
https://codelabs.developers.google.com/codelabs/cloud-kubeflow-pipelines-gis Kubeflow Pipelines (KFP) helps solve these issues by providing a way to deploy robust, repeatable machine learning pipelines along with monitoring, auditing, version tracking, and reproducibility. Cloud AI Pipelines makes it easy to set up a KFP installation.
https://www.kubeflow.org/docs/components/pipelines/introduction/#what-is-kubeflow-pipelines
"Kubeflow Pipelines supports the export of scalar metrics. You can write a list of metrics to a local file to describe the performance of the model. The pipeline agent uploads the local file as your run-time metrics. You can view the uploaded metrics as a visualization in the Runs page for a particular experiment in the Kubeflow Pipelines UI." https://www.kubeflow.org/docs/components/pipelines/sdk/pipelines-metrics/
NEW QUESTION 31
During batch training of a neural network, you notice that there is an oscillation in the loss. How should you adjust your model to ensure that it converges?
- A. Decrease the size of the training batch
- B. Decrease the learning rate hyperparameter
- C. Increase the size of the training batch
- D. Increase the learning rate hyperparameter
Answer: D
Explanation:
https://developers.google.com/machine-learning/crash-course/introduction-to-neural-networks/playground-exercises
NEW QUESTION 32
A data scientist wants to use Amazon Forecast to build a forecasting model for inventory demand for a retail company. The company has provided a dataset of historic inventory demand for its products as a .csv file stored in an Amazon S3 bucket. The table below shows a sample of the dataset.
How should the data scientist transform the data?
- A. Use a Jupyter notebook in Amazon SageMaker to transform the data into the optimized protobuf recordIO format. Upload the dataset in this format to Amazon S3.
- B. Use a Jupyter notebook in Amazon SageMaker to separate the dataset into a related time series dataset and an item metadata dataset. Upload both datasets as tables in Amazon Aurora.
- C. Use ETL jobs in AWS Glue to separate the dataset into a target time series dataset and an item metadata dataset. Upload both datasets as .csv files to Amazon S3.
- D. Use AWS Batch jobs to separate the dataset into a target time series dataset, a related time series dataset, and an item metadata dataset. Upload them directly to Forecast from a local machine.
Answer: B
NEW QUESTION 33
You are working on a Neural Network-based project. The dataset provided to you has columns with different ranges. While preparing the data for model training, you discover that gradient optimization is having difficulty moving weights to a good solution. What should you do?
- A. Use feature construction to combine the strongest features.
- B. Improve the data cleaning step by removing features with missing values.
- C. Use the representation transformation (normalization) technique.
- D. Change the partitioning step to reduce the dimension of the test set and have a larger training set.
Answer: B
NEW QUESTION 34
You work for a public transportation company and need to build a model to estimate delay times for multiple transportation routes. Predictions are served directly to users in an app in real time. Because different seasons and population increases impact the data relevance, you will retrain the model every month. You want to follow Google-recommended best practices. How should you configure the end-to-end architecture of the predictive model?
- A. Write a Cloud Functions script that launches a training and deploying job on Ai Platform that is triggered by Cloud Scheduler
- B. Use Cloud Composer to programmatically schedule a Dataflow job that executes the workflow from training to deploying your model
- C. Configure Kubeflow Pipelines to schedule your multi-step workflow from training to deploying your model.
- D. Use a model trained and deployed on BigQuery ML and trigger retraining with the scheduled query feature in BigQuery
Answer: C
NEW QUESTION 35
Which of the following metrics should a Machine Learning Specialist generally use to compare/evaluate machine learning classification models against each other?
- A. Recall
- B. Area Under the ROC Curve (AUC)
- C. Mean absolute percentage error (MAPE)
- D. Misclassification rate
Answer: B
NEW QUESTION 36
A Machine Learning team uses Amazon SageMaker to train an Apache MXNet handwritten digit classifier model using a research dataset. The team wants to receive a notification when the model is overfitting.
Auditors want to view the Amazon SageMaker log activity report to ensure there are no unauthorized API calls.
What should the Machine Learning team do to address the requirements with the least amount of code and fewest steps?
- A. Implement an AWS Lambda function to log Amazon SageMaker API calls to Amazon S3. Add code to push a custom metric to Amazon CloudWatch. Create an alarm in CloudWatch with Amazon SNS to receive a notification when the model is overfitting.
- B. Use AWS CloudTrail to log Amazon SageMaker API calls to Amazon S3. Set up Amazon SNS to receive a notification when the model is overfitting
- C. Implement an AWS Lambda function to log Amazon SageMaker API calls to AWS CloudTrail. Add code to push a custom metric to Amazon CloudWatch. Create an alarm in CloudWatch with Amazon SNS to receive a notification when the model is overfitting.
- D. Use AWS CloudTrail to log Amazon SageMaker API calls to Amazon S3. Add code to push a custom metric to Amazon CloudWatch. Create an alarm in CloudWatch with Amazon SNS to receive a notification when the model is overfitting.
Answer: C
NEW QUESTION 37
......
Updated Google Study Guide Professional-Machine-Learning-Engineer Dumps Questions: https://validtorrent.prep4pass.com/Professional-Machine-Learning-Engineer_exam-braindumps.html